
Voice Design - The First Generative AI For Audio
The first generative model for creating synthetic voices is here
Last month we announced our generative model for voice creation was coming. It's finally here and it's the first one of its kind - we call it Voice Design. The feature lets you build new voices from scratch by selecting their core qualities like gender, age and accent. And even with the same core parameter settings, our model adds randomness every time you hit generate to ensure each voice you hear is utterly unique. Voice Design is part of our wider effort to equip publishers and creators with the most versatile AI storytelling tools.
Voice Design
The model behind Voice Design is largely the result of our research into speech synthesis and voice cloning, though independently we always liked the idea of a generative tool for speech. We've already seen practical applications for generative text-to-image and chatbot models but a similar tool for audio was missing. Ever since our launch we've been getting requests to add more speakers to our bank. Instead of overcrowding the library with countless voices and making you listen through each preview to know who's who, we decided to flip the script and let you determine speaker identity, all the while allowing for infinite variety within these constraints.
Adding a degree of control to voice selection was important since our users often seek concrete speech characteristics for their scripts. Ensuring each generated voice is unique was equally crucial as many use-cases require, or at least benefit from, having exclusive access to a voice. In addition to providing users with a new creative outlet, voices generated with Voice Design are completely artificial and don’t belong to any real person.
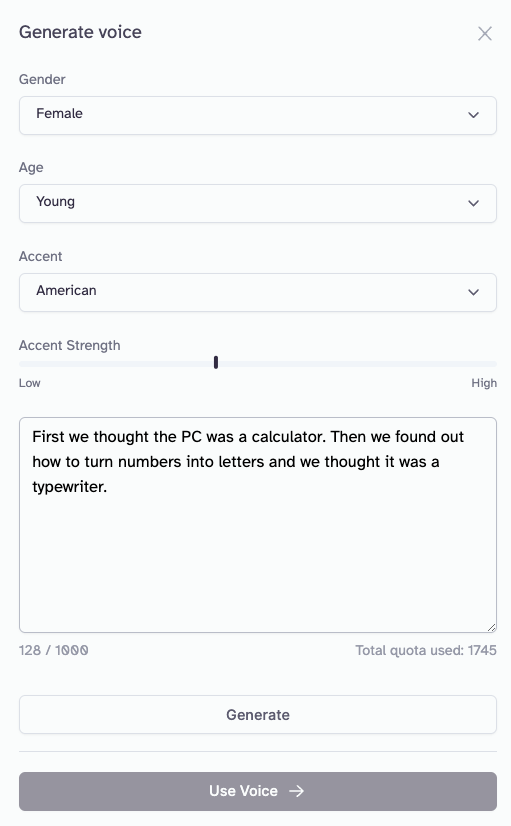
Voice Design Tutorial
The Voice Design interface is extremely simple to use and just requires you to select a few voice qualities and adjust the accent strength toggle.
Hear some of the voices we generated with Voice Design:





Applications
On top of effortlessly converting writing to quality audio with our staple Speech Synthesis tool, book authors can now use Voice Design to exercise artistic control over narration and shape each character's personality with bespoke voices.
News publishers venturing into audio need voices for their stories. Because narrators become identified with the publications they represent, choosing the right voiceover becomes an important task that's not often repeated. Voice Design lets publishers pick and compare virtually countless narrators on the spot. It also gives them the peace of mind of having a particular voice represent them, and them alone.
Game developers no longer need to choose whether a particular character justifies recording costs. Tens of thousands of previously mute NPCs can now have unique personalities, pushing the boundaries of virtual immersion.
Whether you're a content creator working on your next release or a corporate officer looking to voice company communications, the possibilities for designing lifelike, compelling audio for specific use-cases and audiences are now limitless.
Ecosystem
Voice Design is one of multiple features for narration editing we plan to introduce this year. Next is Projects - our new workstation for structuring large texts, inserting pauses, regenerating chunks of audio, and assigning parts of text to different speakers. Projects is coming in late March and it will be supplemented by intonation editing support later in Q2 this year.